Tiny Search Engine
Overview
Overview
This Tiny Search Engine (tse) was made for my final individual project for COSC 50. The purpose of the tse is to simulate how search engines work (albeit on a smaller and simpler scale). The tse is able to crawl through and download webpages from a source, index the words on those pages, and then query and rank the pages based off of search terms. Testing was implemented for every component.
Class
COSC 50: Software Design & Implementation
Timeline
April - May 2022 (4 weeks)
Tools
C, Bash
Features
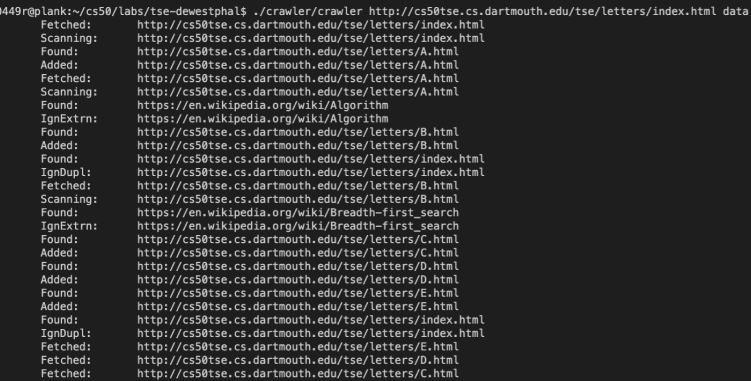
./crawler seedURL pageDirectory max_depth
The crawler takes in a designated seedURL and crawls all pages reachable from that URL up to a specified max_depth. The HTML files of the website that it crawls through are saved to the pageDirectory.
The output of the crawler running on a contained seed url
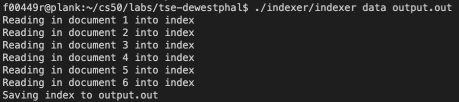
./indexer pageDirectory indexFilename
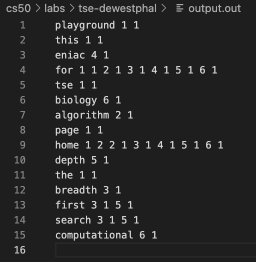
The TSE indexer is a standalone program that reads the document files produced by the TSE crawler, builds an index, and writes that index to a file. An index contains a count of how many time every word appears in each page.
The output of the indexer running on the crawled webpages from above
The output.out file generated; we see webpage number 4 contains the word eniac one time
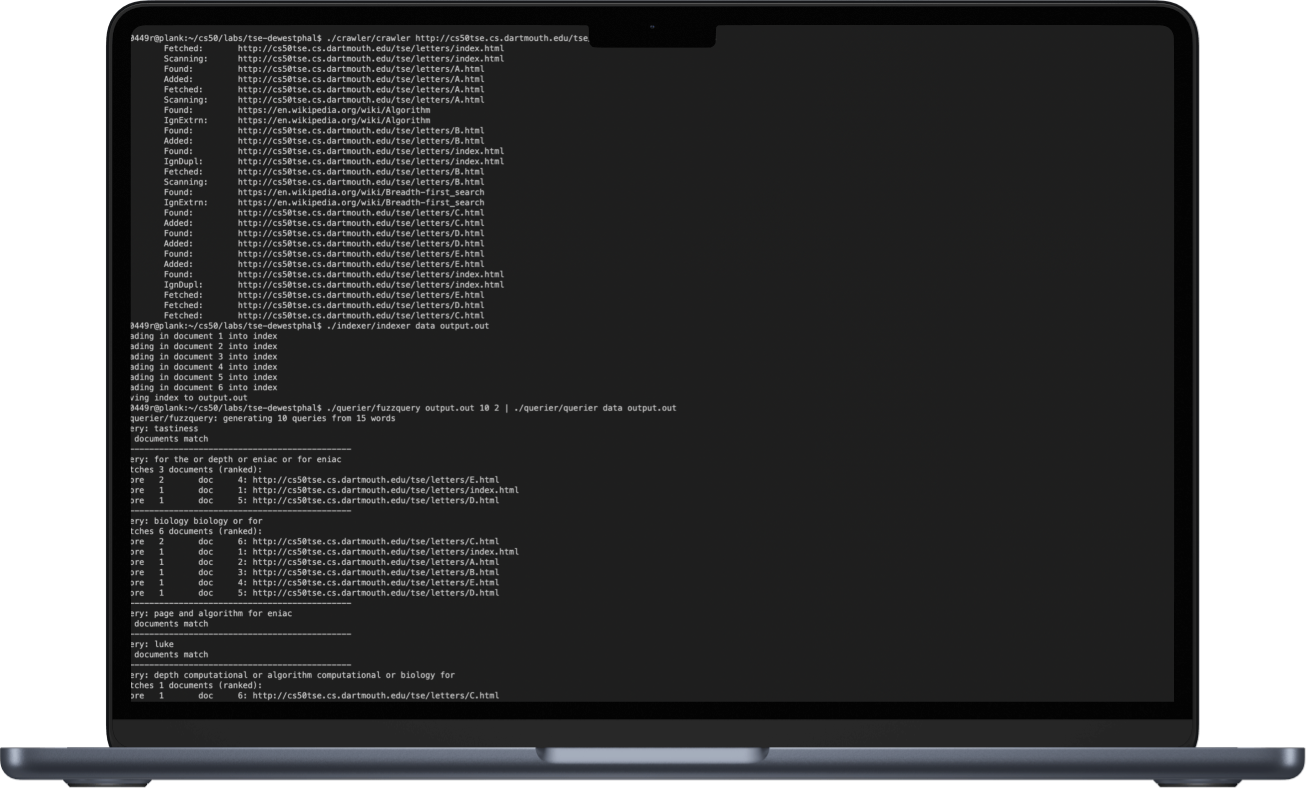
./querier pageDirectory indexFilename
The TSE Querier reads the index produced by the Indexer and the page files produced by the Crawler, to interactively answer written queries entered by the user. Queries can contain logic (e.g. dogs OR cats, dogs AND cats) and results are returned to the user ranked.
The output of the querier; fuzzquery generates random queries to search for to facilitate testing